
This post is divided into 3 parts to simplify the learning process and help understand autoscale and related concepts along with mathematical models on each step. These models will allow visualizing and optimizing of autoscale configurations. In these 3 parts we will focus on the following topics.
- Understanding flapping (current)
- Identifying effective scale-in metrics
- Challenges with memory based metrics
The unpredictability of compute or storage demands of web applications made the Cloud happen. The ability to scale as per your instantaneous requirements and being charged just for those instances is the crux of the pitch for moving to the cloud. This what the autoscaling capabilities of Azure Web Apps help you achieve. Autoscale adds more compute instances (scale-out) or increase the size of your existing instance (scale-up) based on metrics that you define. While scaling out is important for the availability of your service, scaling in is important to keep costs under control.
For example - you may choose to add 1 new instance to your App Service Plan if the CPU usage remains above 90% consumption for more than 15 minutes. While scaling up is great, it is also important for your App Service Plan to scale down once peak traffic is over and the stress on your application starts receding. So you can choose to reduce 1 instance from your App Service Plan if the average CPU usage across all instances reduces below 80%.
This summarizes the autoscaling capability; however, the behaviour of the metrics and thresholds that define your autoscale rules can be slightly nuanced. Let’s build on top of the previous example.
- Assume that the application started receiving high volume of requests at 6:00am continuing to increase average CPU usage to 90% until 6:30am. This will trigger the scale-out rule a couple times, adding 2 instances to the App Service Plan making the total instance count 4.
- The traffic is now shared by 4 instances and average CPU usage drops to 80% while the same volume of traffic continues.
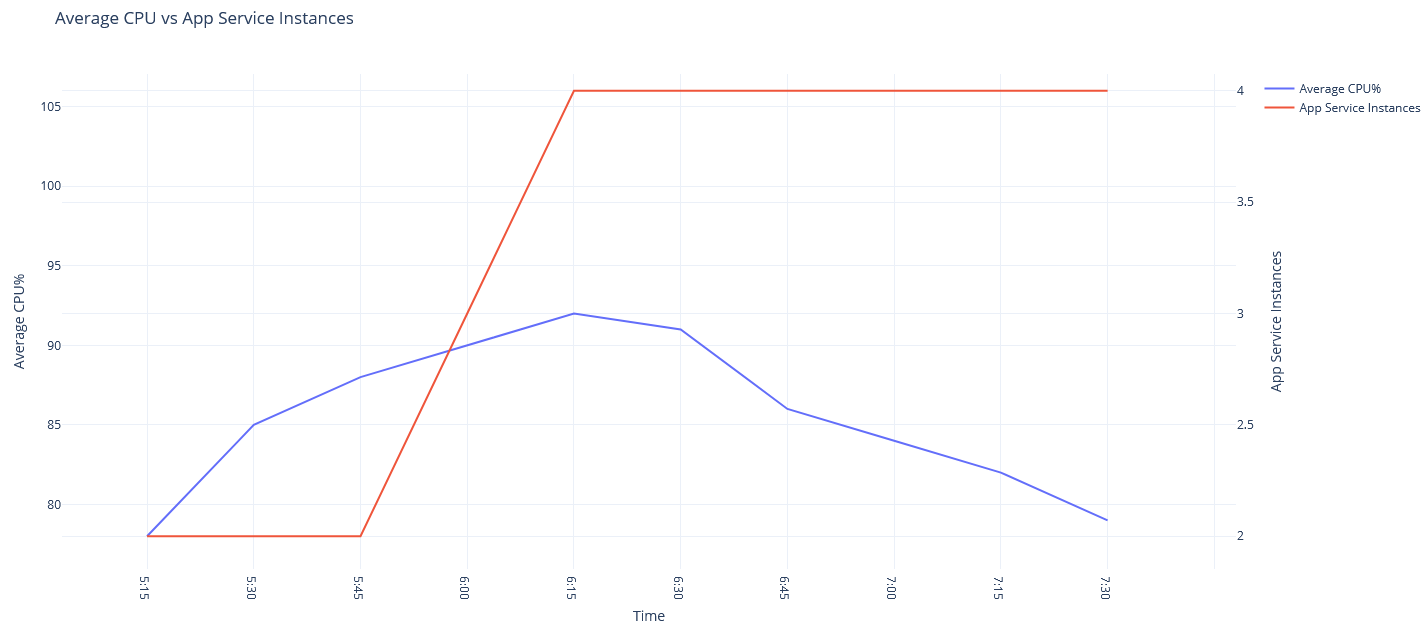
- At 7:30am traffic gradually starts receding and average CPU usage drops to 79% eventually triggering the scale-in rule reducing the instance count to 3.
While this might seem expected, let’s understand implications here. A total of 4 instances where signalling average CPU usage of 79%. Reducing a single instance with existing traffic will lead to (4 x 79) / (4 - 1) = 105.33% average CPU usage. This is far less than ideal behaviour and will eventually create a scale-in, scale-out loop as seen below starting 7:30 or even worse, crash the application servers.
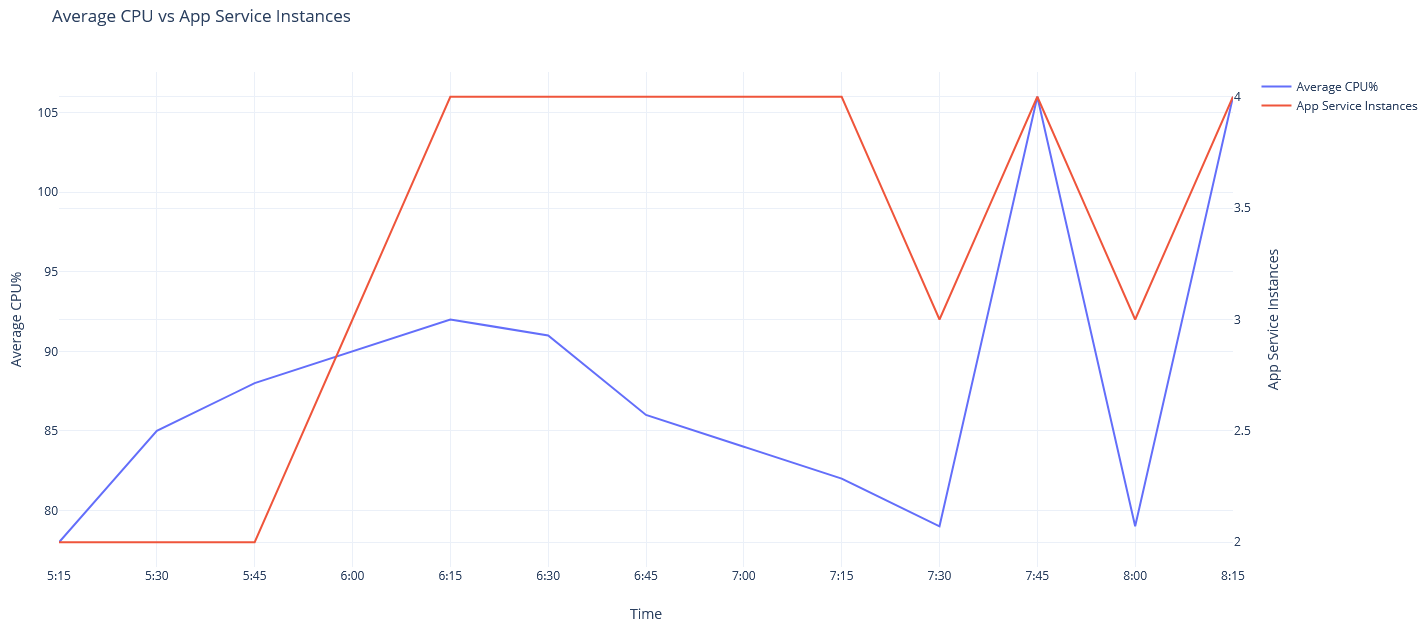
Azure understands that this will lead to unhealthy application performance and therefore implements anti-flapping measures. i.e. before performing any autoscale operation, Azure predicts if the operation will trigger other contradicting operations. If the answer is yes, the operation is cancelled and you will end up seeing “Flapping” in your autoscale operation logs. The autoscale operation in practice looks as below.
How do you prevent flapping?
While anti-flapping measures on Azure protect you, it is a good practice to take calculated steps to keep these events predictable and rare.
In the above example we have default 2 instances and scale instance is 1. Which is essentially adding 50% more compute. At peak operating point, there are 4 allocated instances. Scale-in of 1 instance causes 25% drop in compute capacity. Flapping would not be observed under the same autoscale configuration above if the peak number of allocated instances was 10. Meaning the configurations is suitable if the services normally operates with 10 or more allocated instances. Most common occurrence of flapping is found when the ratio of scale instances to operating instances is high or scale-in and scale-out thresholds are too close. A mathematical model can help paint a clear picture.
We consider the number of instances being added or removed in a single autoscale operation as Scale instances (s), the number of instances being used at any point in time as allocated instances (x) and scale-in scale-out thresholds (ti, to respectively).
In the graphs below, the X-axis indicates allocated instances while the Y-axis indicates the autoscale metric (average CPU% in this case). The green line is the scale-in threshold while the red line is the scale-out threshold.
Scaling in
The plot (blue) uses the following equation to calculate the resulting scale-in metric (ri) considering the current metric has reached the scale-in threshold (ti).
ri = (x * ti) / (x - s)
Autoscale will operate a scale-in if the metric falls below 80%. Flapping can be observed for all scale-in operations when the allocated instances are less than 9. In this range the metric shoots above the 90% scale-out threshold which will trigger a scale-out immediately. Therefore, Azure will prevent the scale-in operation with its anti-flapping measures. This does not mean scale-in does occur at all. It simply means that the metric will have to fall lower for scale-in to actually take effect.
Scale out
More instances don’t hurt an application so scale-out will work as per thresholds. Autoscale does not block scale-out operations as part of the anti-flapping mechanism. The costs still apply so it is at least insightful to apply the math for scale-out too.
The plot (purple) uses the following equation to calculate the resulting scale-out metric (ro) considering the current metric has reached the scale-out threshold (to).
ro = (x * to) / (x + s)
It can be observed that scale-out works optimally for all scale-out operations above 8 allocated instances.
Tune it
With the model in front of us, we can now tweak our autoscale settings considering the traffic patterns on our services. Feel free to click on the Desmos link on the graph below to play around with the autoscale configurations to find a sweet spot for your autoscale configurations.
In the next part we will discuss an approach to identify effective scale-in metrics.
Ideas presented here are based on my personal observations. Please maintain caution when applying configurations on your own cloud environments. Your results might vary. Got feedback or ideas? drop a comment or email om [at] 0x8 dot in.
{kind=link}